Today I was lucky enough to present at the State of the Map US conference in Detroit, Michigan. The topic is near to my heart, the education initiatives of the American Geographical Society, specifically, the growing relationship between AGS Geography Teacher Fellows and the OpenStreetMap community. The slides are posted below, and the talk was filmed so expect the video will be here. Ultimately we asking for help from the OSM community to help AP Human Geograpy teachers with technical support around mapathons. If interested, sign up here: bit.ly/AGSmapathons
Support Geographic Education with OpenStreetMap and the American Geographical Society
A core tenet of the American Geographical Society (AGS) is expanding geographic education. To that end the AGS, and its corporate partners, have established the Geography Teacher Fellows program, and over the last three years have directly engaged with 150 Advanced Placement (AP) Human Geography teachers across the United States. A key piece of the Geography Teacher Fellows engagement is the introduction of OSM mapping and mapathons to the human geography curriculum. The response to this TeachOSM-led training has been overwhelmingly positive, but teachers have been limited in their adoption of OSM mapping by the technical hurdles of conducting a mapathon. To address this gap, AGS is looking for volunteers from the OSM community that would like to be paired up with AP Human Geography teachers in their area. The idea is that a local mapper would work directly with a local AP Human Geography teacher to put on a mapathon, to provide onsite tutorials, or to simply be available to answer questions of students and teachers in their locality. For more information, see the AGS website (https://americangeo.org/initiatives/ags-geography-teacher-fellows/) or sign up directly online (http://bit.ly/AGSmapathons)
This year’s Free and Open Source for Geospatial (FOSS4G) North America event was held in Raleigh, NC between May 2-5, 2016. Attendance increased by 150+ over last year, bringing the total to over 550 registrations. While typically a developer conference with technical software presentations, recent years has seen an increase in participation (both attendance and presentations) from the user community. This year continued that trend, and the agenda included a wide array of topics. In addition to good facilities and well run logistics, the program committee did an excellent job curating the presentations; nearly all of the sessions I attended were appropriate content and well delivered, a feat for any conference. A full list of the attended sessions I attended is in the table at the end of the post.
Below are some of my takeaways from the conference, categorized into three general themes: Tools, Data, and Visualization.
Tools
It is clear that open source software continues to mature, and when combined with new deployment technologies like Docker containers and cloud, it is a fundamentally different world than a few years ago. This is clearly not a ground shaking statement, but the speed by which anyone can go from zero to a cloud-deployed, scalable geographic computing infrastructure is amazing.
Machine Learning is everywhere. Granted I haven’t used ML approaches in a few years, but my concern is that simpler approaches of statistical modeling are being overlooked just to use the big, new shiny thing. The underlying assumption with ML is that all problems are solved best through inductive methods, which potentially discounts the wisdom of domain expertise. ML is obviously very powerful when lots of data is available and should be part of the modelling toolkit, but it’s not a magic bullet and mis-applications are going to become more common. Using TensorFlow or the other new algorithms doesn’t fundamentally change the need to understand how statistics and modeling works, and modelers need to be aware of the full range of statistical tools.
On the Natural Language Processing (NLP) and geocoding side, GeoParser could be key bridge between the document open data and geospatial open data communities. Combining tools like Apache Tika, Stanford NLP, and Gazetteer lookup means there is a single toolkit with the potential to geocode any document. Clearly geocoding results here are limited in success to the quality of the gazetteer, but the processing pipeline is interesting.
The Geo Big Data processing tools continue to mature and are even starting to converge on the use of underlying libraries and database. This collection of tools includes GeoWave, GeoTrellis, GeoMesa, GeoJinni. Personally I’m interested in the use of GeoTrellis for high-performance raster modeling.
Sensors are expanding everywhere: agriculture best example of persistent, integrated data collection across sensors (imagery, lidar, IoT) and application into “smart” devices (self-driving farm equipment and custom planting / harvesting strategies). OpenSensorHub can be used to integrate various feeds, thinking of applications with automated hydromet, weather, and seismic stations, as well as other crowd reported data feeds.
Data
Vector tiles expand market share: nascent analytical capability, new version 2.0 specification, true 3D in the tile (when comes 4D), added to GeoServer
Remote Sensing is big: Cubesats, Drones, Imagery, Point Clouds all continue to grow and expand into all market verticals (farming, logistics, business analysis leading the way)
Remote Sensing is still hard: massive imagery catalogs only further expose fundamental remote sensing issues on analysis (orthorectification and image-to-image registration, atmospheric effects on spectral reflectance); drones and kites driving new photogrammetric toolkits; the cool kids are yet to fully catch on to these challenges.
OSM ecosystem continues to deepen and expand: Portable OpenStreetMap, or POSM, is a nice tool for enabling disconnected editing in austere environments. The upgraded HOT Export Tool is a key part of exporting the initial datasets used for the process. The critical question is how to get data back into OSM. Currently all edits are manually reviewed, using an interesting queuing mechanism that maintains individual changesets, and then uploaded using an import account. The question is how will the method scale when remote mapping is occurring at the same time as field mapping, the potential disconnect between edit histories of the disconnected branch can and will be an issue.
Visualization
Vector tiles is driving more client side rendering. Mapbox obviously leading the way here, but Boundless now supporting vector tiles in GeoServer and OpenLayers.
Seamless 2D/3D visualization: Cesium is everywhere, TerriaJS interesting library to add better visualization on top of spatial data catalogs; USGS/NASA GIBS adding atmospheric data slices into dense imagery catalogs. When do we get 4D tiles and/or tiles with multiple versions of the same dataset?
Imagery is driving client side visualization and nascent imagery exploitation tools in the browser
Convergence of ground based and aerial based views: “painted” 3D models from photogrammetric extraction combined with Mapillary type imagery; farm management using ground and aerial lidar clouds.
Sessions
Each of the links below go to the FOSS4G session page, many of which have links to the slidedecks and in the coming weeks will have the video recording of the presentation.
The Ito World crew is back at it with a new OpenStreetMap visualization, this time for Africa. Results are shown at the continental scale and for selected cities over the last couple years. The final product is stunning, as usual.
Growth in West Africa as part of the Ebola response, and the Nigeria eHealth Import are the most distinctive. Other growth areas include a broad swath of East Africa, and the incredible density of the Map Lesotho project. Most impressive, however, is that the growth is not constrained to these areas; it is distributed across the continent. The missing areas are gradually filling in, it is only a matter of time…
It all started with delicious pancakes and a glorified misconception. In a 2003 article published in the Annals of Improbable Research (AIR), researchers claimed to scientifically prove that “Kansas is Flatter Than a Pancake” . The experiment compared the variation in surface elevation obtained from a laser scan of an IHOP pancake and an elevation transect across the State of Kansas. And while the researchers’ conclusion is technically correct, it is based on two logical fallacies. First, the scale the analysis shrunk the 400 mile-long Kansas elevation transect down to the 18 cm width of the pancake, thereby significantly reducing the variability of the elevation data. Second, pancakes have edges, which creates some significant relief relative to the size of the pancake, approximately 70 miles (!) of elevation if applied to Kansas scale (Lee Allison, Geotimes 2003). Using this approach, there is no place on earth that is not flatter than a pancake.
Now, I can take a joke, and at the time thought the article was clever and funny. And while I still think it was clever, it began to bother me that the erroneous and persistent view that Kansas is flat, and therefore boring, would have negative economic consequences for the state. I grew up on the High Plains of southwestern Kansas, where there are broad stretches of very flat uplands. But even within the High Plains region there are areas with enough relief to certainly not be considered flat as a pancake…and this doesn’t include the other two-thirds of the state.
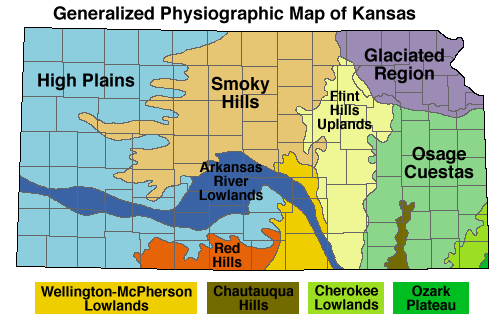
Official Physiographic Regions for the State of Kansas. Note the large number of regions denoted by “hills.”
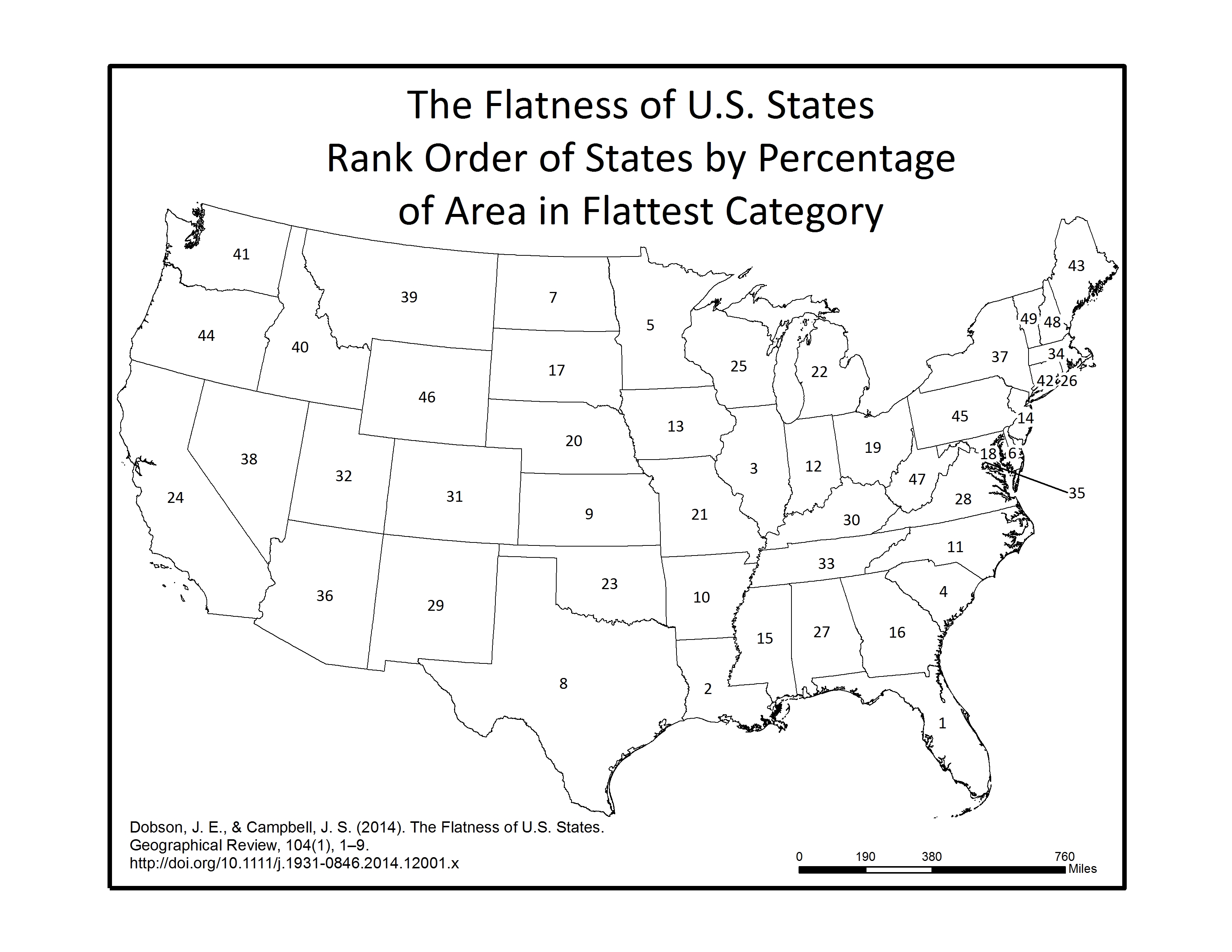
The joke of it is that the official Physiographic Regions of Kansas Map describes the majority of the state in terms of hills: Flint Hills, Red Hills, Smoky Hills, Chautauqua Hills, Osage Cuestas (Spanish for “hills”). Not to mention the very hilly Glaciated Region of northeastern Kansas, anyone who attended classes on Mount Oread can confirm that for you. And after travelling through other areas of the country, I realized that Kansas isn’t even close to the flattest state.
As luck would have it, a few years after the AIR article I found an opportunity to work on this question of flatness and how to measure it. As part of my PhD coursework I was investigating the utility of open source geospatial software as a replacement for proprietary GIS and needed a topic that could actually test the processing power of the software. Combining my background in geomorphology and soil science with a large terrain modeling exercise using the open source stack offered the perfect opportunity to address the question of flatness. What emerged from that work was published last year (2014) in the Geographical Review as a paper coauthored with Dr. Jerry Dobson entitled “The Flatness of U.S. States” .
The article is posted below, so I won’t rewrite it here, but the central goals were twofold. First, create a measure of flatness that reflected the human perception of flat. This measure needed to be based on how humans perceive flatness, quantitatively based, repeatable, and globally applicable. Second, understand how the general population of the U.S. thinks about flat landscapes, and if there was a bias towards assuming Kansas was the flattest state. This blog post focuses more on the details associated with the first goal, while the article posted below has the description of The American Geographical Society’s Geographic Knowledge and Values Survey that provided data for the second.
Methodology
There were many measures of flat that had been developed in the geomorphological literature, but they tended to be localized measures, meant for hydrological and landscape modeling. I wanted something that could capture the sense of expanse that you feel in a very flat place. Beginning with that thought, I tried to imagine a perfect model of flatness. It had to expand in all directions and be vast. The mental model was that of being on a boat in flat seas and looking out at nothing but horizon in all directions. With a little research, I discovered there is an equation for determining how far you can see at sea. It is height dependent, both for the observer and the object of observation, and it calculates that a 6 foot / 1.83 m tall person, looking at nothing on the landscape (object of observation = 0 ft), can see 5,310 meters before the curvature of the earth takes over and obscures view. This was a critical variable to determine, the distance measure for capturing the sense of “flat as a pancake” is 5,310 meters (at a minimum).
A conceptual model of flatness.
With perception model and distance measure in hand, I needed to determine what the appropriate digital elevation model to use. Even though the study area for this paper is the Lower 48 of the United States, a global dataset was needed so that the methodology could be applied globally. The NASA Shuttle Radar Topography Mission (SRTM) data that had been processed by the Consortium of International Agricultural Research Centers (CGIAR) Consortium for Spatial Information (CSI) was the best choice. Specifically 90 meter resolution SRTM Version 4.1 was used, and is available here: http://srtm.csi.cgiar.org/.
In terms of software, the underlying goal of this project was to use only open source software to conduct the analysis. This meant I had to become familiar with both Linux and the QGIS and GRASS workflows. I built an Ubuntu virtual machine in Virtual Box (eventually switching to VMware Workstation) with QGIS 1.2 and Grass 6.3 with the QGIS plugin; by the time I finished the project I was using Ubuntu 10.04, QGIS 1.8 and GRASS 6.4 (and sometimes GRASS 7.0 RC). You don’t realize how much “button-ology” becomes ingrained until you have to switch toolkits, and the combined Windows to Linux and ESRI to QGIS/GRASS transition was rough at times. There were times I knew I could complete a task in seconds in ArcGIS, but spent hours figuring out how to do it in QGIS and GRASS. However, it is worthwhile to become facile in another software as it reinforces that you have to think about what you are doing before you start pushing buttons.
The open source stack has come a long way since I started this project back in 2009, with usability being the greatest improvement. It is a lot easier now for a mere mortal to get up and running with open source than it was then, and the community continues to make big strides on that front. From a functionality standpoint, I did some comparisons between GRASS (Windows install) and ArcGIS 9.2 GRID functions and found that they were very equivalent in terms of processing speeds. It seems there are only so many ways to perform map algebra; note, I discuss the new game-changing approaches to distributed raster processing at the end.
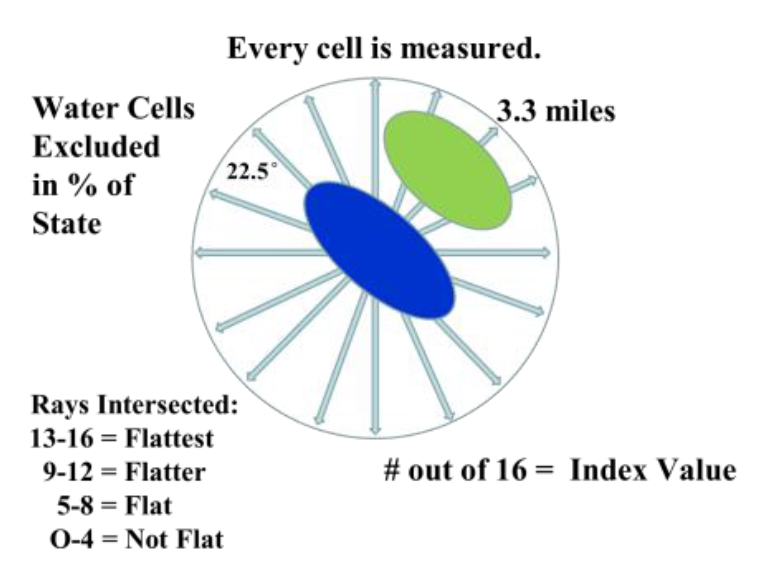
The first attempts to model flatness used a nested approach of slope and relief calculations run at different focal window sizes that were then combined into an index score. However, they just didn’t seem to work that well. To start I was only working on a Kansas subset and compared various model outputs to places I knew well. In researching other analysis functions I came across the r.horizon algorithm. Originally designed for modeling solar radiation, it has an option that traces a ray from a fixed point at a set azimuth, out to a set distance, and measures the angle of intersection of the ray and the terrain. Discovering this function changed my whole approach; it automatically incorporated the distance measure and was only concerned with “up” terrain. To model flat, r.horizon needed to be run for 16 different azimuths, each 22.5 degrees apart, to complete the full 360 degree perspective. Additionally it needed to be run for every raster cell. The output was then 16 different layers, one for each azimuth, with the intersection angle of the ray and the terrain.
Graphic displays how the Flat Index is calculated for every 90 meter cell, using independent measures collected across 16 different directions.
Next I had to determine at what angular measurement flat stopped being flat. This is a subjective decision and one based on my experience growing up on the High Plains. On a return trip to my hometown I surveyed a number of places to get a feel for what was truly flat and what wasn’t. Upon reviewing the topographic maps of those areas, I determined that an upward rise of 100 ft / 30 meters over a distance of 3.3 miles was enough to stop the feeling of “flat as a pancake.” This correlated to an angular measure of 0.32 degrees. Now this measure is completely arbitrary, and it would be interesting to get how others would classify it. I did review it with a few other western Kansas natives who agreed with me. Note, we were not concerned with down elevation at all. This is because canyons and valleys do not impact the perception of flatness until you’re standing near the edge; anyone who’s been a mile away from the South Rim of the Grand Canyon can confirm that you don’t know its there.
Graphic displays the angular measure criteria (0.32 degree) used to make the binary flat/not flat classification.
The data processing for this project was massive, requiring downloading all the individual tiles of the SRTM for the Lower 48 (55 tiles, over 4GB in total size), importing (r.in.gdal), mosaicing (r.patch), setting regions (g.region), then ultimately subsetting into four sections because of a bug in r.horizon (r.mapcalc conditional statements), running r.horizon 16 times on every raster cell in the Lower 48 (1,164,081,047 cells), running the cut point reclassification (r.recode), then compiling the final index score (r.mapcalc). Each segment of the DEM took about 36 hours to process in r.horizon, meaning the entire Lower 48 took about 6 days total.
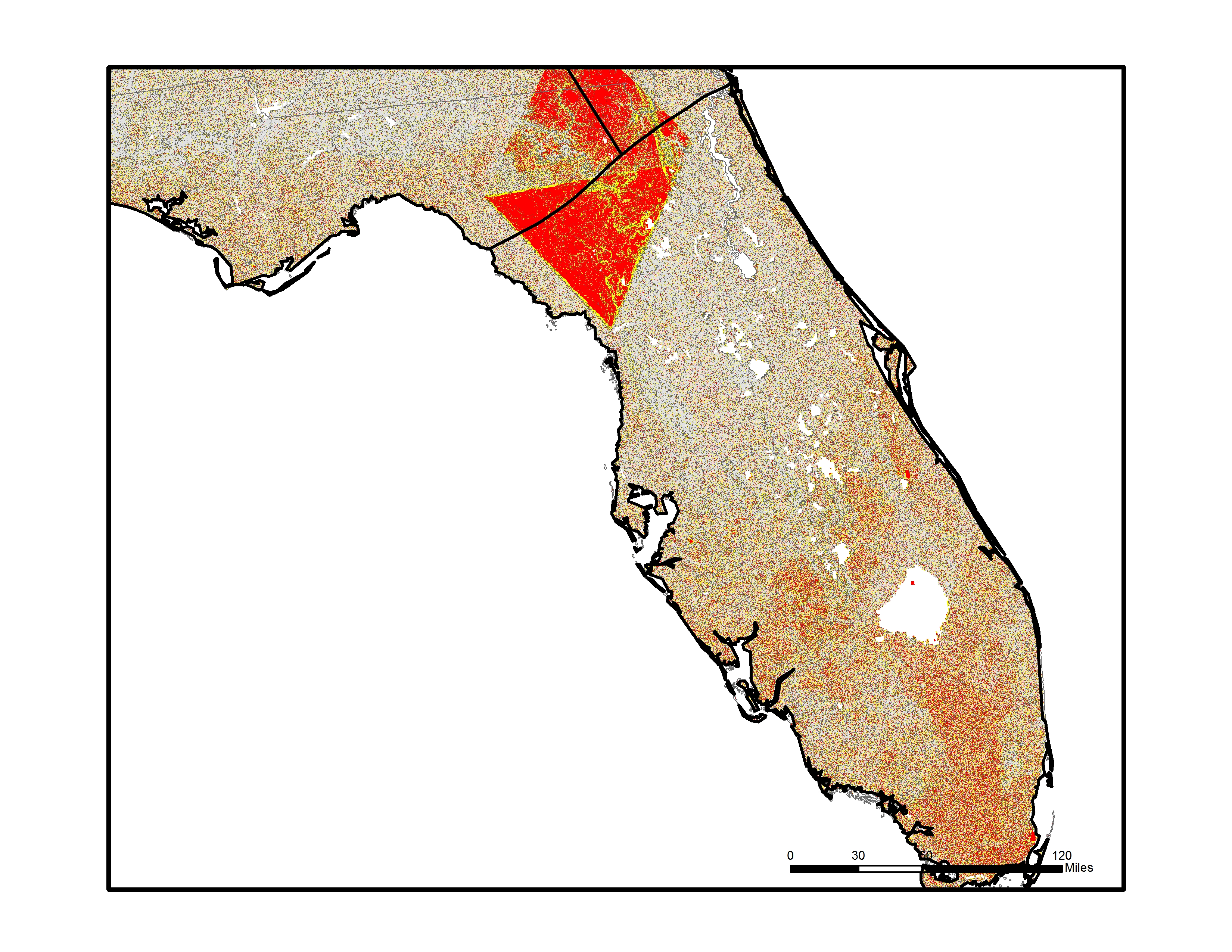
In the final step, each of the 16 individual azimuth scores were added together (r.mapcalc) to create a single index score ranging from 0-16 (0 being non-flat in all directions, 16 being flat in all directions). This index score was divided into four groupings, with Not Flat (0-4), Flat (5-8), Flatter (9-12), Flattest (13-16) categories. Zonal statistics (r.statistics) for each state were extracted from the final flat index, also known as the “Flat Map”, to calculate the rankings for flattest state. A water bodies data layer was used as a mask in the zonal statistics (r.mask) so as to eliminate the impact of flat surface water elevations (reservoirs and lakes) from the final calculation. A second mask was also used to eliminate the influence of two areas of bad data located in the southeastern U.S., mainly in Florida and South Carolina. Both total number of flat pixels and percent area flat pixels were calculated and ranked for the flat, flatter, and flattest categories. See the article below for a table of results.
Results
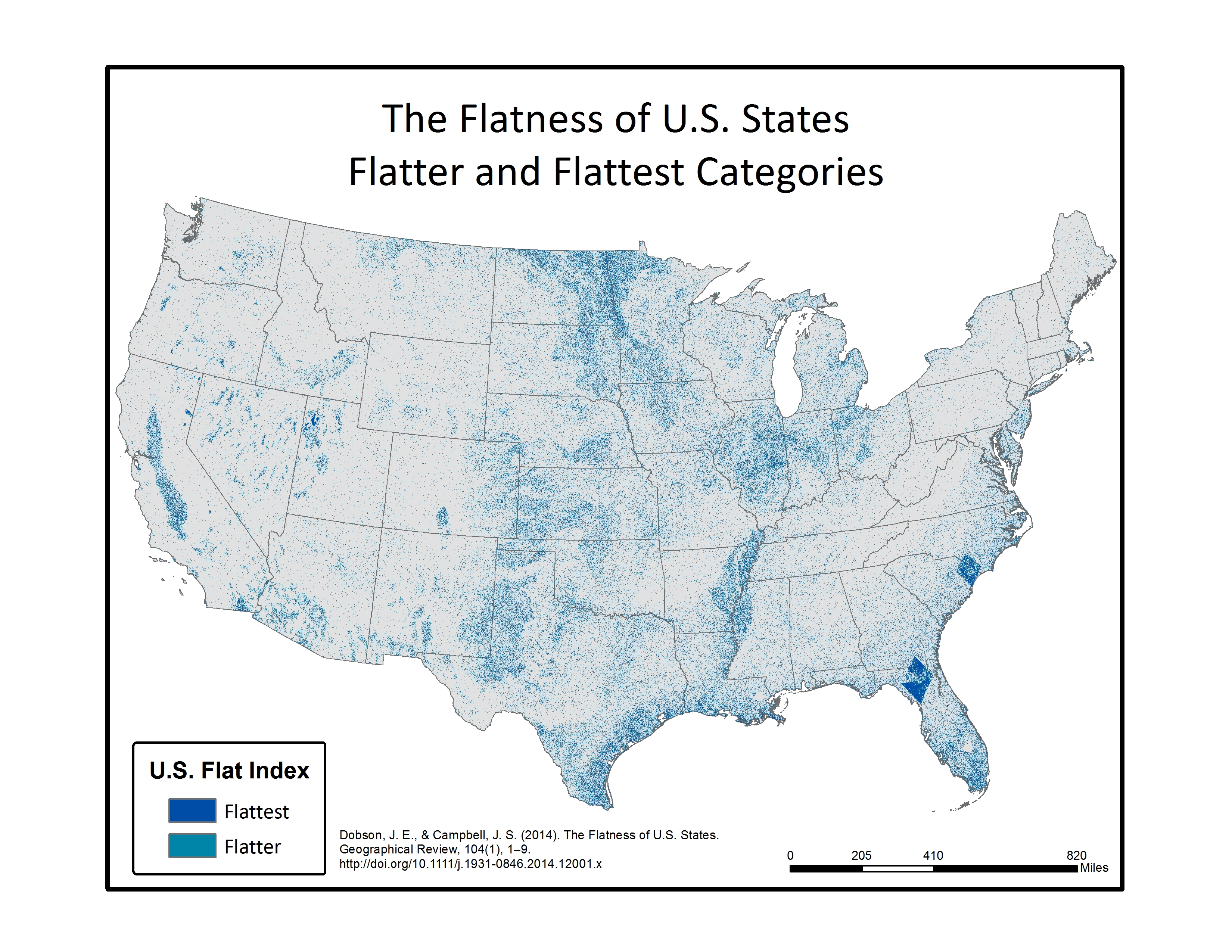
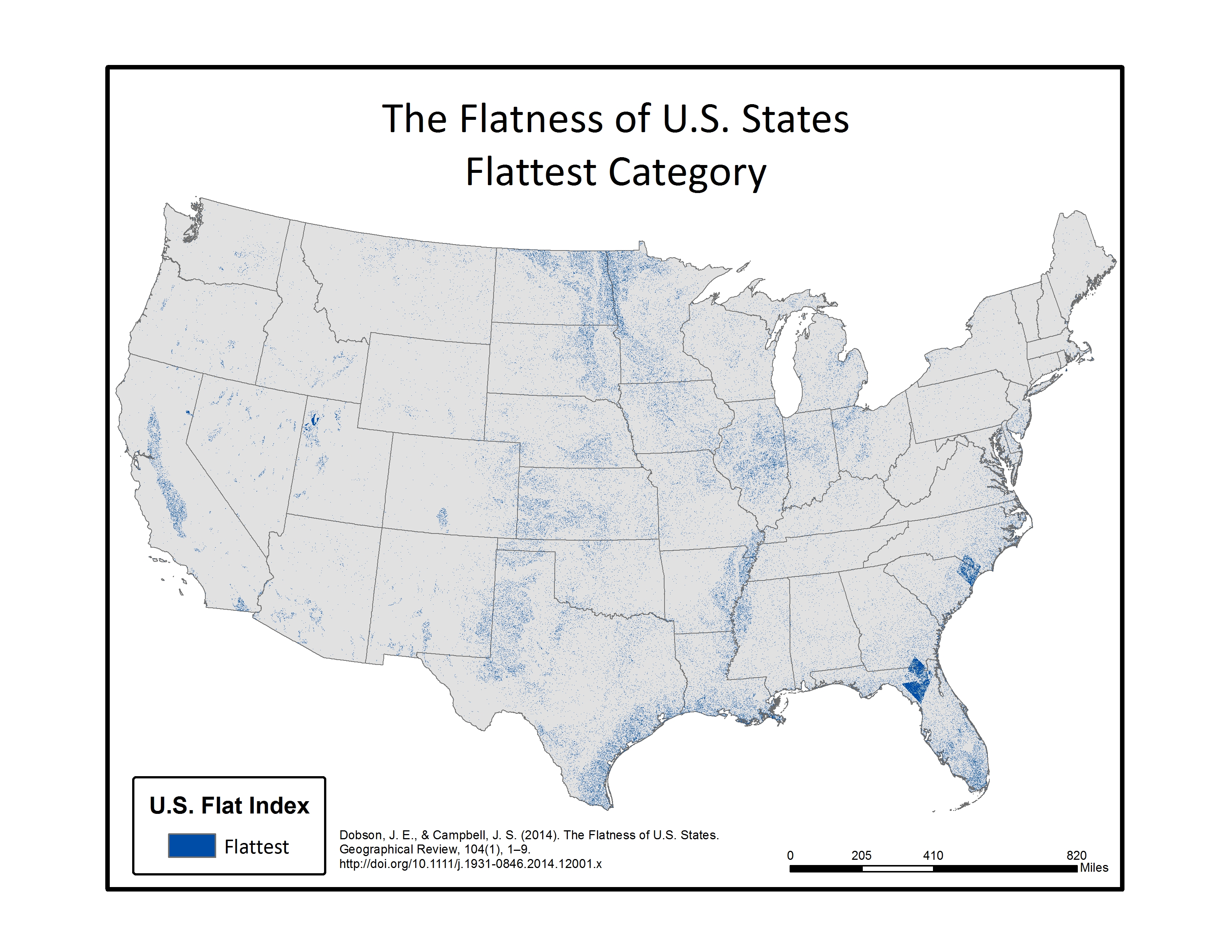
Below are a series of maps that display the final Flat Index. The spatial distribution of flat areas is intriguing, with some confirmations and surprises to our initial hypotheses. Interesting areas include the Piedmont and coastal plains of the eastern coastal states, Florida and the coastal areas of the Gulf States, the Red River Valley in Minnesota and North Dakota, the glacial outwash in Illinois and Indiana, the Lower Mississippi River valley, the High Plains region of the Great Plains, the Basin and Range country of the Intermontain West, and the Central Valley of California. A complete table of the state rankings is available in the article, and there are several more zoomed in maps available below. Each image is clickable and will open a much larger version.
Map shows the Flat Index, a.k.a the “Flat Map”, for the Lower 48 of the United States.Map displays the Flatter and Flattest Categories of the Flat Index. Useful for visualizing the patterns of flat lands within the continental United States.Map displays the Flattest Category of the Flat Index. These are the areas that can be called “flat as a pancake.”Rank order of States by the percentage of their area in the Flattest class. As initially thought, Kansas isn’t even close to the flattest.
Media
The media response to what Jerry Dobson, my coauthor and PhD advisor, and I refer to as the “Flat Map” took me by surprise. Jerry was always confident it would be well received, but the range of international, national, and regional coverage it received was beyond anything I imagined…and it keeps going.
As an added bonus, in the spring of 2017 renowned science blogger Vsauce featured the Flat Map in the a video about “How Much of the Earth Can You See at Once” (see video below). With over 4.5M views so far, this has to be most coverage the Flat Map has received. I recommend the entire video, and the Flat Map section begins around the 10:30 mark.
And this little gem from the 2015 Kansas Official Travel Guide…that’s right, the Flat Map made the Tourism Guide. In the very chippy AIR response to the Flat Map, the AIR editors indicate they got a call from the Kansas Director of Tourism. I’ll take this.
Does the perception of flatness impact tourism? Seems the State of Kansas is interested in projecting that the Kansas landscape has hills.
More Maps
Map shows the Flat Index for the Lower 48 of the United States overlaid with the boundaries of the USGS Physiographic regions. Interesting correlation between flat areas and physiographic boundaries.Map displays the Flat Index over Florida, note large areas of flat land in southern half of the state and along the panhandle coast.Map shows the Flat Index over Louisiana and the Lower Mississippi Valley. Large areas of flat lands occur within the river valley and along the coastal areas.Map shows the Flat Index over Illinois and Indiana. Note the huge area of Illinois within the Flattest class, the result of glacial outwash geomorphic processes.Map shows the Flat Index over northern Texas and Oklahoma. Note large tracts of flat land in the western High Plains region.Map shows the Flat Index over Kansas. Note large areas of flat land in the western High Plains region and in the central area of the state corresponding to the Arkansas River valley and McPherson-Wellington Lowlands physiographic province.
Thanks
I would like to thank Dr. Jerry Dobson for his efforts on this paper. We worked together conceptualizing “flat” and how to build a novel, terrain-based, and repeatable method for measuring it. It was a long road to get the Flat Map out to the world, and Jerry was a constant source of inspiration and determination to get it published. When I was swamped with work at the State Department, Jerry pushed forward on the write up and talking with the media.
Future
In terms of the future, there is much more that can be done here. New distributed raster processing tools (Mr. Geo and GeoTrellis) could rapidly increase processing speeds, and provide an opportunity for using a more refined, multi-scalar approach to flatness. New global elevation datasets are also becoming available, and could potentially reduce the error of the analysis through lower margins of error in forested areas. If I was to do it again, the USGS National Elevation Datasets, particularly at the 30 meter and even 10 meter resolution, would be a great option for the United States. On the perception front, the terrain analysis results could be compared with landcover data to determine how landcover affects perception. Social media polling could also gather a huge amount of place-based data on “Is your location flat?” and “Is your location boring?”. I would also like to get the data hosted on web mapping server somewhere, so people could interact with it directly. A tiled map service and the new Cesium viewer would be a great tool for exploring the data. If anyone is interested in working together, let me know.
Article
Below is a pre-publication version of the article submitted to Geographical Review. Please cite the published version for any academic works.
Adding to the collection of amazing OpenStreetMap animations, the folks at Scout worked with the Ito World team to create a new addition to the “Year in Edits” series. Celebrating the 10 year anniversary of OpenStreetMap, the new video looks at the growth in OSM between 2004 to 2014 . As I’ve blogged before, I love these videos. The production quality is high, music is great, and they provide an easy way to communicate how amazing the OSM database has become. Kudos to all the volunteer mappers out there.
I posted a comment about my concerns regarding the automatic installation of the SAGA and OTG dependencies, and Riccardo answered that the Windows install does include both. I haven’t tested it yet, but automatically including them would be great. Would appreciate if anyone could confirm this in the Windows install, and if the Ubuntu install has been updated.
As likely everyone in the geo world knows by now, the widely awaited release of QGIS 2.0 was announced at FOSS4G this week. Having closely watched the development of QGIS 2.0 I was eager to get it installed and take a look at the new features. I am for the most part a Windows user, but I like to take the opportunity to work with the open source geo stack in a Linux environment. My Linux skills are better than a beginner, but because I don’t work with it on a daily basis, those skills are rusty. So I decided this is a good excuse to build out a new Ubuntu virtual machine, as I haven’t upgraded since 10.04.
Build Out The Virtual Machine
Let’s just say I was quickly faced with the challenges of getting Ubuntu 12.04 installed in VMware Workstation 7.1. Without getting into details, the new notions of “Easy Install” and its effect on installing VMware Tools took a while to figure out. In case anyone has the Easy Install problem, this YouTube video has the answer, also posted in code below:
The second problem, about configuring VMware Tools with the correct headers, is tougher. I’m still not sure I fixed it, but given its rating on Ask Ubuntu, it’s obviously a problem people struggle with. Suffice it to say there is no way that I could have fixed this on my own, nor do I really have a good understanding of what was wrong, or what was done to fix it.
The Open Source Learning Curve
This leads me to the point with this post, open source is still really tricky to work with. The challenges in getting over the learning curve leads to two simultaneous feelings: one, absolute confusion at the problems that occur, and two, absolute amazement at the number of people who are smart enough to have figured them out and posted about it on forums to help the rest of us. While its clear the usability of open source is getting markedly better (even from my novice perspective), it still feels as if there is a “hazing” process that I hope can be overcome.
QGIS 2.0 Installation
With that in mind, here is some of what I discovered in my attempt to get QGIS 2.0 installed on the new Ubuntu 12.04 virtual machine. First, I followed the directions from the QGIS installation directions, but unfortunately I was getting errors in the Terminal related to the QGIS Public Key, and a second set on load. Then I discovered the Digital Geography blog post that had the same directions, plus a little magic command at the end (see below) that got rid of the on load errors.
sudo chown -R "your username" ~/.qgis2
After viewing a shapefile and briefly reviewing the new cartography tools, I wanted to look at the new analytical tools. But there was a problem, and they didn’t load correctly. So back to the Google, and after searching for a few minutes I found the Linfinty Blog on making Ubuntu 12.04 work with QGIS Sextante. After a few minutes downloading tools I check again, this time the image processing tools are working, but I keep getting a SAGA configuration error. After figuring out what SAGA GIS is, and reading the SAGA help page from the error dialog box, it was back to searching. The key this time was a GIS Stack Exchange post on configuring SAGA and GRASS in Sextante, this time the code snippet of glory is:
sudo ln -s /usr/lib64/saga /usr/lib/saga
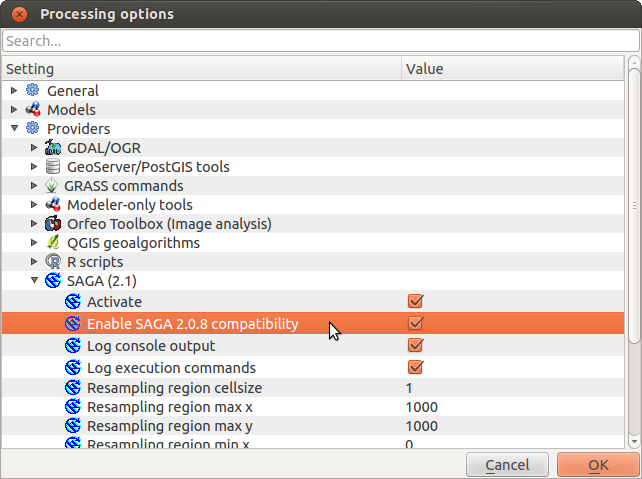
Next, back to QGIS to fire up a SAGA powered processing routine, and the same error strikes again. More searching and reading, now its about differences in SAGA versions and what’s in Ubuntu repos. With no clear answer, I check the Processing options in which there is an “Options and Configuration”, which has a “Providers” section, which as an “Enable SAGA 2.0.8 Compatibility” option. Upon selecting the option, boom, the all the Processing functions open. Mind you I haven’t checked whether they actually work, after several hours they now at least open.
“Processing” configuration options in QGIS 2.0
Conclusion
It is clear that the evolution of open source geo took several steps forward in this last week, and the pieces are converging into what will be a true end-to-end, enterprise-grade, geographic toolkit. And while usability is improving, in my opinion, it is still the biggest weakness. Given the high switching costs for organizations and individuals to adopt and learn open source geo, the community must continue to drive down those costs. It is unfair to ask the individual developers who commit to these projects to fix the usability issues, as they are smart enough to work around them. Seems to me it is now up to the commercial users to dedicate resources to making the stack more usable.
‘Disruption is a theory: a conceptual model of cause and effect that makes it possible to better predict the outcomes of competitive battles in different circumstances’ — The Innovators Solution
My PhD dissertation at the University of Kansas is entitled “The Disruptive Potential of GIS 2.0: An application in the humanitarian domain”. The research involves several interrelated philosophical, technological, and methodological components, but at its core, it is about building a new way to harness the power of geographic analysis. In short, the idea is to show how Geographic Information Systems (GIS) has evolved into something different than it was before, explore the dynamics of that evolution, then build new tools and methods that capitalize on those dynamics.
The foundation of the argument is that a new generation of digital geographic tools, defined here as GIS 2.0, have completely changed how core GIS processes are implemented. While the core functions of a GIS remain the same — the creation, storage, analysis, visualization, and dissemination of geographic data — the number of software packages capable of implementing spatial functions and the distribution capacity of the Internet have fundamentally changed the desktop GIS paradigm. Driving GIS 2.0 is a converging set of technology trends including open source software, decreasing computation costs, ubiquitous data networks, mobile phones, location-based services, spatial database, and cloud computing.The most significant, open source software, has dramatically expanded access to geographic data and spatial analysis by lowering the barrier to entry into geographic computing. This expansion is leading to a new set of business models and organizations built around geographic data and analysis. Understanding how and why these trends converged, and what it means for the future, requires a conceptual framework that embeds the ideas of the Open Source Paradigm Shift and Commons-based Peer Production within the larger context of Disruptive Innovation Theory .
While there is a philosophical element to this argument, the goal of the dissertation is to utilize the insights provided by disruptive innovation theory to build geographic systems and processes that can actually make a difference in how the humanitarian community responds to a complex emergency. It has been long recognized that geographic analysis can benefit the coordination and response to complex emergencies , yet the deployment of GIS has been hampered by a set of issues related to cost, training, data quality, and data collection standards . Using GIS 2.0 concepts there is an opportunity to overcome these issues, but doing so requires new technological and methodological approaches. With utility as a goal, the research is structured around general three sections:
GIS 2.0 Philosophy: Exploring the fundamental reorganization of GIS processes, and building a conceptual model, based on disruptive innovation theory, for explaining that evolution and predicting future changes
GIS 2.0 Technology: Utilizing GIS 2.0 concepts build the “CyberGIS”, a geographic computing infrastructure constructed entirely from free and open source software
GIS 2.0 Methodology: Leverage the CyberGIS and GIS 2.0 concepts to build the “Imagery to the Crowd” process, a new methodology for crowdsourcing geographic data that can be deployed in a range of humanitarian applications
In the next series of posts I will explore each of the points above. My goal is to complete the dissertation in the coming months and I want to use this blog as a staging ground for drafts, chapters, and articles that can be submitted to my committee. As such they will likely be a bit rough. I am a perfectionist in my writing, which only serves to completely slow down my productivity, so hopefully this will force me to “release early and often.”
The core arguments of GIS 2.0 were originally conceived during 2006-2008, so they are a bit dated now. At the time there was really only anecdotal evidence to support the argument that the same Web 2.0 forces that built Wikipedia and disrupted the encyclopedia market were going to impact GIS. However, with the continued rise of FOSS4G, OpenStreetMap, and now the Humanitarian OpenStreetMap Team (HOT), it feels almost redundant to be making this argument now. Additionally, from the technology perspective there are lots of individuals and groups out there doing more cutting edge work than I ever will, but I hope the combination of philosophical approach and actual implementation can be a contribution to the discipline of geography — and more importantly, help the humanitarian community be more effective.
Benkler, Y. 2002. Coase’s Penguin, or, Linux and “The Nature of the Firm.” Yale Law Journal 112 (3):369–446.
Christensen, C. M., and M. E. Raynor. 2003. The Innovator’s Solution: Creating and Sustaining Successful Growth. Boston: Harvard Business School Publishing.
Clarke, K. C. 2001. Getting started with geographic information systems 3rd ed. Upper Saddle River, N.J: Prentice Hall.
Kelmelis, J. A. ;, L. Schwartz, C. Christian, M. Crawford, and D. King. 2006. Use of Geographic Information in Response to the Sumatra-Andaman Earthquake and Indian Ocean Tsunami of December 26, 2004. Photogrammetric Engineering and Remote Sensing 72:862–876.
National Research Council. 2007. Successful response starts with a map: improving geospatial support for disaster management. Washington, D.C: National Academies Press.
O’Reilly, T. 2007. What is Web 2.0: Design Patterns and Business Models for the Next Generation of Software. Communications & Strategies 1:17. http://ssrn.com/abstract=1008839 (last accessed 22 January 2013).
von Hippel, E. 2005. Open Source Software Projects as User Innovation Networks. In Perspectives on Free and Open Source Software, eds. J. Feller, B. Fitzgerald, S. A. Hissam, and K. R. Lakhani, 267–278. Cambridge: MIT Press http://mitpress.mit.edu/books/perspectives-free-and-open-source-software.
One of the interesting things about the “Imagery to the Crowd” projects has been the positive feedback we have received from a range of different communities. Ultimately we built the process from a belief that free and open geographic data could support the effective provision of humanitarian assistance, and that the power of open source software and organizations were the key to doing this efficiently.
Our goal with Imagery to the Crowd is to provide a catalyst, in the form of commercial high-resolution satellite imagery, to enable the volunteer mapping community to produce data in areas experiencing (or in risk of) a complex emergency. In many ways I thought of this process as trying to link the “cognitive surplus” of the crowd with the purchasing power of the United States Government, to help humanitarian and development organizations harness the power of geography to do what they already do better.
Somewhat surprisingly, a community outside of the humanitarian sector recognized the potential impact of this process, and the HIU was awarded the United States Geospatial Intelligence Foundation (USGIF) Government Achievement Award 2012 (Press Release, Symposium Daily pdf, Video page). The award was presented at the GeoInt Symposium in Orlando, FL (Oct 7-14 2012). Below is a video of the awards presentation, and includes the Academic and Industry Division winners from this year. The section on the HIU begins around the 7:25 mark.
—————————
—————————–
At the conference I also was on a panel in a “GeoInt Forward” session focused on open source software. This panel was actually the best part of the conference. Typically the first day of the GeoInt Symposium is reserved for the golf event, but this year the organizers included an additional day of panel sessions. In general these sessions were very well attended, and with a full-house of approximately 250 people the session on Open Source Software exceeded my expectations. The session description and other panelists are listed below, and it is clear the defense and intelligence perspective that is GeoInt, but it was an interesting group doing work across a range of different applications. I tried to provide a bit of balance and discussed the philosphical approach to open source, and its potential as an organizing principle for organizations. The Imagery to the Crowd project is built on an a cloud-hosted open source geographic computing infrastructure, so I could speak to the reality of this system. It seems that the coming budget austerity has generated significant interest in open source, and now could be golden opportunity.
From the conference proceedings:
“Open Source Software (OSS) has moved from being a backroom, developers-only domain to a frontline component inside key military capabilities. OSS isn’t doing everything—yet—but it is slowly commoditizing key strategic parts of geospatial infrastructure, from operating systems to databases to applications. In this session, key government program managers will discuss where and how they see OSS moving to solve warfighter needs, as well as assess the gaps in OSS investment and capabilities.”
Moderator – John Scott, Senior Systems Engineer & Open Tech Lead, RadiantBlue
Panelists
• John Snevely, DCGS Enterprise Steering Group Chair
• Col Stephen Hoogasian, U.S. Air Force, Program Manager, NRO
• Keith Barber, Senior Advisor, Agile Acquisition Strategic Initiative, NGA
• John Marshall, Chief Technology Officer, J2, Joint Staff
• Dan Risacher, Developer Advocate, Office of the Chief Information Officer, DoD
• Josh Campbell, GIS Architect, Office of the Geographer & Global Issues, State Department
Here is my ignite talk on the “Imagery to the Crowd” project from the International Conference on Crisis Mapping (ICCM 2012). I’ve attended each of the four ICCM conferences (Cleveland, Boston, Geneva, Washington DC). They have been a great way to understand the organizations that comprise the humanitarian community, and more importantly, meet the individuals who power those organizations. It was exciting to present on our work at the HIU, and contribute back to the Crisis Mapping community.
All of the Ignite talk videos are available at the Crisis Mappers Website(lineup .pdf) and collectively they represent a solid cross-section of the field. At the macro-level, I believe the story continues to be about the integration of these new tools and methodologies into established humanitarian practices. The toolkits are stabilizing (crowdsourcing, structured data collection using SMS, volunteer networks, open geographic data and mapping, social media data mining) and are being adopted by the major humanitarian organizations. While I am partial towards crowdsource mapping, the Digital Humanitarian Network and the UN OCHA Humanitarian eXchange Language (HXL) are two other exciting projects.