A recent article on the most remote places in America struck a cord with me. The article, published by the Washington Post, utilizes recent work on global travel times that models the transportation networks between any two places on earth, using a range of transportation options. This work, A global map of travel time to cities to assess inequalities in accessibility in 2015, is a tremendous achievement of spatial data aggregation, topological connectivity, and spatial modeling, and is worthy of a post in and of itself.
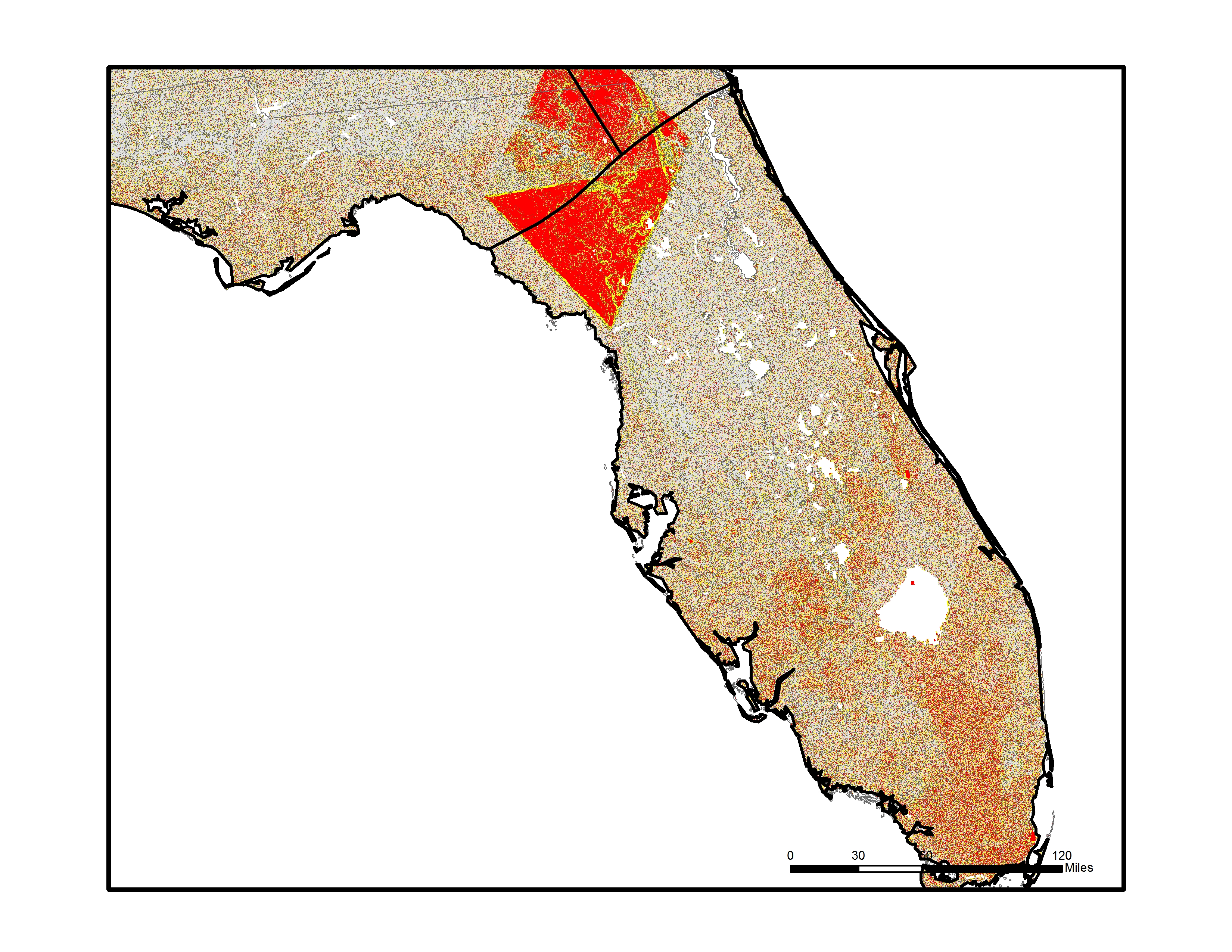
That said, it was the work done by the Post , using the Global travel time data to determine remote places in the United States that caught my attention. In looking at the map (Figure 1 below), it takes a second to understand what is being modeled. The details are spelled out quite clearly in the article, but of course, I looked through the map first.
Figure 1: Map of travel times in the United States, originally from Washington Post article published February 20, 2018
When you think of “remote”-ness, the first thing the comes to mind is a desolate mountain cabin or desert camp. And the map above does highlight the two places with the longest travel times in the Lower 48. However, this is an absolute value of remoteness, a one way path. The more interesting component of this analysis is the comparative definition of remote…where the travel time between two actual locations is calculated. The desolate mountain cabin is the domain of a single person…what does it mean to be remote when you live in an actual town?
In this analysis, the travel time between every location in the Lower 48 U.S. and the nearest metropolitan area (city with a population greater than 75,000) is derived from the Global travel data. This creates a continuous surface where every 1,000m x 1,000m grid cell contains a travel time. When mapped, this data forms a type of “travel-shed” map that is reminiscent of hydrologic and watershed maps. Commensurately, the boundaries of the travelsheds are the areas with the largest travel times, and help delineate regional zones where a particular city is dominant. The travel speed of various transport modes are also reflected in the data, e.g., interstates are faster than secondary highways, and that fact imprints a pattern where the fastest paths resemble river valleys in the travelsheds. Finally, the ridges between travelsheds provides the “remote” areas, farthest away from population centers.
From a macro perspective, the highly populated eastern U.S. shows much lower variation in travel times when compared with the more sparsely populated areas of the Great Plains, Rocky Mountains, and intermontane areas of the western states. This is a combination of higher overall population and a fairly even distribution of populated places…essentially there are so many people that it’s hard to get too far from a larger town. Notable areas of high travel times include the intermontane areas of Utah and Nevada, the Trans-Pecos region of West Texas, and an interesting ridge through the mid continent that roughly follows the western extent of the High Plains physiographic region.
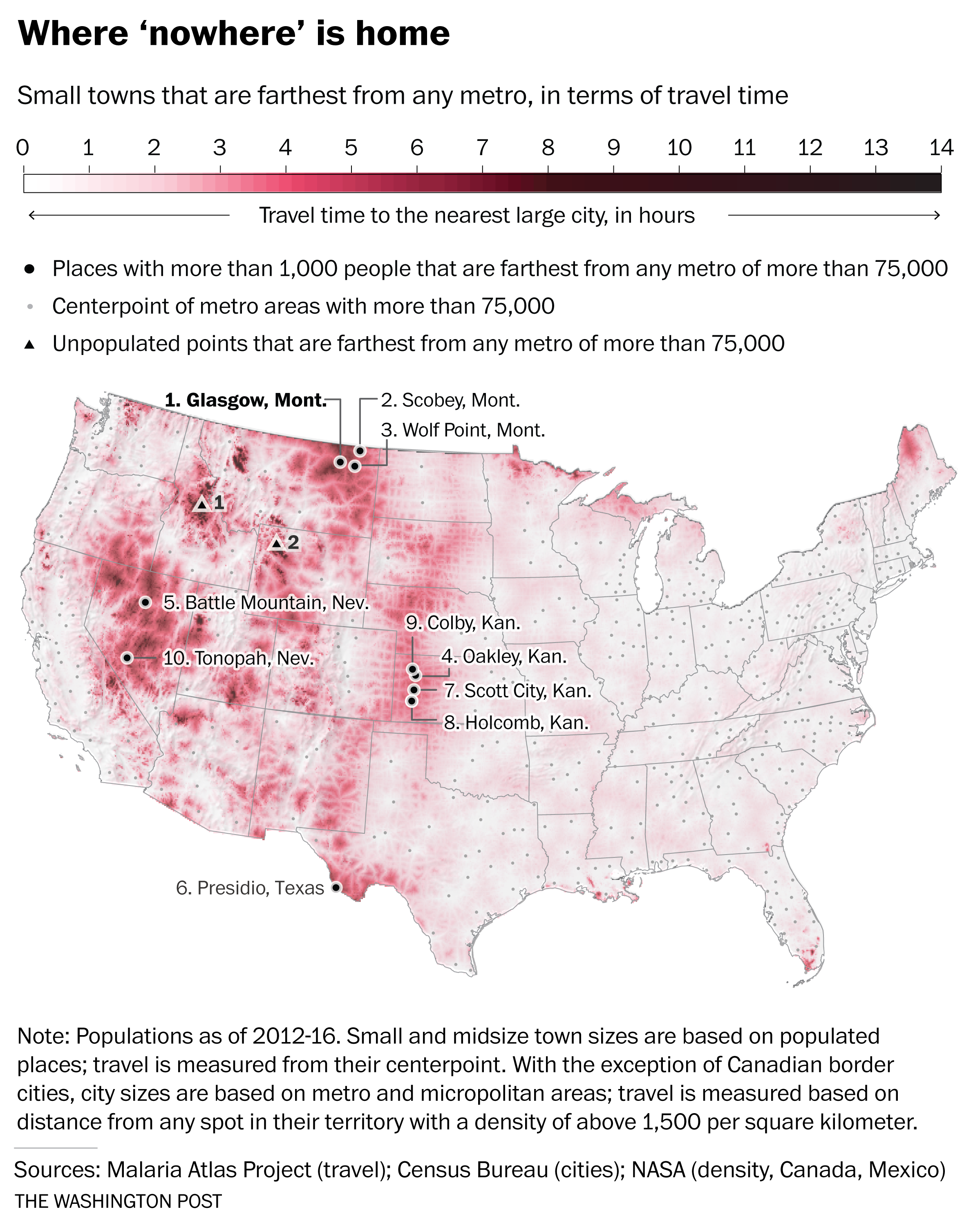
In the next step of the analysis, the travel time layer is intersected with the location of all American cities greater than 1,000 people, and the travel time between the small city and the nearest city of 75,000 people was calculated. Brilliant. In fact, they did the same analysis comparing towns with population larger than 1,000, 5,000, and 25,000. The ranked list of cities is displayed in Figure 2 below.
Figure 2: Ordered list of most remote towns in the Lower 48 U.S., with the Kansas High Plains towns highlighted (added for this blog post). Originally published in the Washington Post article published February 20, 2018
So why is this significant to me? Beyond being a super slick GIS application, two other reasons. First, I grew up in southwest Kansas, an area that I have often described to people as being about as far away from anything as you can get in this country…and it turns out, I was right. My hometown is #10 on the list…and four other locations in the top 10 of the small towns list are its neighbors. Additionally, other towns in southwest Kansas top the most remote in the mid- and large- town lists. The longitudinal ridge of “remoteness” that extends along the 107 degree west longitude line seems to be a “travel-shed” boundary between the populated places of the Colorado Front Range and those in eastern Kansas.
The second interesting element of this analysis is how it compares to my previous work on “flatness”. I haven’t done any quantitative work on this, but a visual comparison of the two maps seems to show a bimodal distribution of remote places…they are either very flat or very not flat. Conjecture could lead one to intuit that flat places are remote because they may be uninteresting to live, while not flat place are remote because it is difficult to get to them.
But I think that is simplistic, the flat remote places are instead driven by the economic geography of the region. For southwest Kansas, that means an economy dominated by agriculture…a lifeway that increasingly requires less and less people, but that still demands population centers at regular intervals to efficiently collect and transport the harvests. This leads to the mix of low population, that is regularly dispersed, and occupies flat terrain. Compare this to the remote area of central Nebraska, which is also on the 107 degree meridian, but that doesn’t appear in this list because there are no settlements that exceed 1,000 people. The Sand Hills mean there is no agriculture, no economic lifeway that requires any substantial grouping of people.
In conclusion, this list of towns reads like a schedule of summer swim meets from my youth…and it’s just bizarre to see it spelled out in a national newspaper. These places that I know well, that I spent significant parts of my life studying the archaeological and climatic past of…are in fact, some of the most remote, yet connected, places in the United States. And now having spent almost 10 years in DC, I’ve come to appreciate just how far the cultural distance is between these remote outposts and the populated centers of the coastal U.S.
The human geographies that occupy these urban / rural divides is tremendous, and there is no clear path between them. Communication technology has shrunk these distances, whether it be the satellite dishes that were prevalent in my youth, or the internet now, technology has homogenized the cultural experience to a large degree…overcoming the limitations of spatial distance. But these areas do feel “remote”, they are a long way, both in culture and travel distance, from the economic and cultural engines of our society.
It is interesting that the original goal of the global travel time data was to assess the inequalities that become manifest when the accessibility to cities is limited. The value of this data for the Sustainable Development Goals (SDG) is clear, and I think will be used in a myriad of ways to plan and contextualize international development efforts. But what does it mean for our society, what does being remote inside the United States mean? What inequalities will become manifest for our own citizens as accessibility to cities remains limited? Maybe this map should be used for some domestic sustainable development?
And while it was the personal connection to my life that drew me to this work, it is clear the data and methodology presented here do offer an valuable framework for understanding the implications of population distribution. In the SDG context, the use of these spatial tools will positively impact development planning and execution, and the team who compiled this data should be applauded. The geospatial revolution continues…
It all started with delicious pancakes and a glorified misconception. In a 2003 article published in the Annals of Improbable Research (AIR), researchers claimed to scientifically prove that “Kansas is Flatter Than a Pancake” . The experiment compared the variation in surface elevation obtained from a laser scan of an IHOP pancake and an elevation transect across the State of Kansas. And while the researchers’ conclusion is technically correct, it is based on two logical fallacies. First, the scale the analysis shrunk the 400 mile-long Kansas elevation transect down to the 18 cm width of the pancake, thereby significantly reducing the variability of the elevation data. Second, pancakes have edges, which creates some significant relief relative to the size of the pancake, approximately 70 miles (!) of elevation if applied to Kansas scale (Lee Allison, Geotimes 2003). Using this approach, there is no place on earth that is not flatter than a pancake.
Now, I can take a joke, and at the time thought the article was clever and funny. And while I still think it was clever, it began to bother me that the erroneous and persistent view that Kansas is flat, and therefore boring, would have negative economic consequences for the state. I grew up on the High Plains of southwestern Kansas, where there are broad stretches of very flat uplands. But even within the High Plains region there are areas with enough relief to certainly not be considered flat as a pancake…and this doesn’t include the other two-thirds of the state.
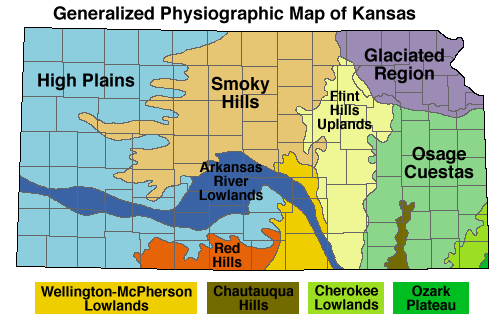
Official Physiographic Regions for the State of Kansas. Note the large number of regions denoted by “hills.”
The joke of it is that the official Physiographic Regions of Kansas Map describes the majority of the state in terms of hills: Flint Hills, Red Hills, Smoky Hills, Chautauqua Hills, Osage Cuestas (Spanish for “hills”). Not to mention the very hilly Glaciated Region of northeastern Kansas, anyone who attended classes on Mount Oread can confirm that for you. And after travelling through other areas of the country, I realized that Kansas isn’t even close to the flattest state.
As luck would have it, a few years after the AIR article I found an opportunity to work on this question of flatness and how to measure it. As part of my PhD coursework I was investigating the utility of open source geospatial software as a replacement for proprietary GIS and needed a topic that could actually test the processing power of the software. Combining my background in geomorphology and soil science with a large terrain modeling exercise using the open source stack offered the perfect opportunity to address the question of flatness. What emerged from that work was published last year (2014) in the Geographical Review as a paper coauthored with Dr. Jerry Dobson entitled “The Flatness of U.S. States” .
The article is posted below, so I won’t rewrite it here, but the central goals were twofold. First, create a measure of flatness that reflected the human perception of flat. This measure needed to be based on how humans perceive flatness, quantitatively based, repeatable, and globally applicable. Second, understand how the general population of the U.S. thinks about flat landscapes, and if there was a bias towards assuming Kansas was the flattest state. This blog post focuses more on the details associated with the first goal, while the article posted below has the description of The American Geographical Society’s Geographic Knowledge and Values Survey that provided data for the second.
Methodology
There were many measures of flat that had been developed in the geomorphological literature, but they tended to be localized measures, meant for hydrological and landscape modeling. I wanted something that could capture the sense of expanse that you feel in a very flat place. Beginning with that thought, I tried to imagine a perfect model of flatness. It had to expand in all directions and be vast. The mental model was that of being on a boat in flat seas and looking out at nothing but horizon in all directions. With a little research, I discovered there is an equation for determining how far you can see at sea. It is height dependent, both for the observer and the object of observation, and it calculates that a 6 foot / 1.83 m tall person, looking at nothing on the landscape (object of observation = 0 ft), can see 5,310 meters before the curvature of the earth takes over and obscures view. This was a critical variable to determine, the distance measure for capturing the sense of “flat as a pancake” is 5,310 meters (at a minimum).
A conceptual model of flatness.
With perception model and distance measure in hand, I needed to determine what the appropriate digital elevation model to use. Even though the study area for this paper is the Lower 48 of the United States, a global dataset was needed so that the methodology could be applied globally. The NASA Shuttle Radar Topography Mission (SRTM) data that had been processed by the Consortium of International Agricultural Research Centers (CGIAR) Consortium for Spatial Information (CSI) was the best choice. Specifically 90 meter resolution SRTM Version 4.1 was used, and is available here: http://srtm.csi.cgiar.org/.
In terms of software, the underlying goal of this project was to use only open source software to conduct the analysis. This meant I had to become familiar with both Linux and the QGIS and GRASS workflows. I built an Ubuntu virtual machine in Virtual Box (eventually switching to VMware Workstation) with QGIS 1.2 and Grass 6.3 with the QGIS plugin; by the time I finished the project I was using Ubuntu 10.04, QGIS 1.8 and GRASS 6.4 (and sometimes GRASS 7.0 RC). You don’t realize how much “button-ology” becomes ingrained until you have to switch toolkits, and the combined Windows to Linux and ESRI to QGIS/GRASS transition was rough at times. There were times I knew I could complete a task in seconds in ArcGIS, but spent hours figuring out how to do it in QGIS and GRASS. However, it is worthwhile to become facile in another software as it reinforces that you have to think about what you are doing before you start pushing buttons.
The open source stack has come a long way since I started this project back in 2009, with usability being the greatest improvement. It is a lot easier now for a mere mortal to get up and running with open source than it was then, and the community continues to make big strides on that front. From a functionality standpoint, I did some comparisons between GRASS (Windows install) and ArcGIS 9.2 GRID functions and found that they were very equivalent in terms of processing speeds. It seems there are only so many ways to perform map algebra; note, I discuss the new game-changing approaches to distributed raster processing at the end.
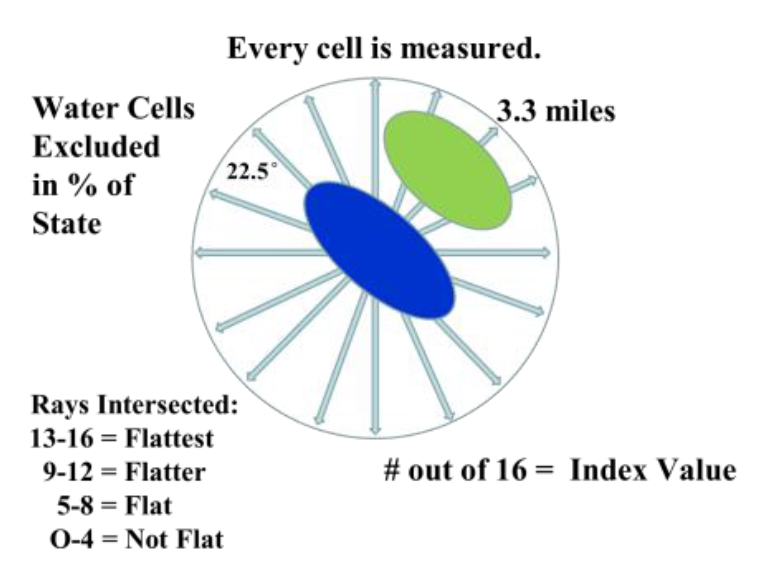
The first attempts to model flatness used a nested approach of slope and relief calculations run at different focal window sizes that were then combined into an index score. However, they just didn’t seem to work that well. To start I was only working on a Kansas subset and compared various model outputs to places I knew well. In researching other analysis functions I came across the r.horizon algorithm. Originally designed for modeling solar radiation, it has an option that traces a ray from a fixed point at a set azimuth, out to a set distance, and measures the angle of intersection of the ray and the terrain. Discovering this function changed my whole approach; it automatically incorporated the distance measure and was only concerned with “up” terrain. To model flat, r.horizon needed to be run for 16 different azimuths, each 22.5 degrees apart, to complete the full 360 degree perspective. Additionally it needed to be run for every raster cell. The output was then 16 different layers, one for each azimuth, with the intersection angle of the ray and the terrain.
Graphic displays how the Flat Index is calculated for every 90 meter cell, using independent measures collected across 16 different directions.
Next I had to determine at what angular measurement flat stopped being flat. This is a subjective decision and one based on my experience growing up on the High Plains. On a return trip to my hometown I surveyed a number of places to get a feel for what was truly flat and what wasn’t. Upon reviewing the topographic maps of those areas, I determined that an upward rise of 100 ft / 30 meters over a distance of 3.3 miles was enough to stop the feeling of “flat as a pancake.” This correlated to an angular measure of 0.32 degrees. Now this measure is completely arbitrary, and it would be interesting to get how others would classify it. I did review it with a few other western Kansas natives who agreed with me. Note, we were not concerned with down elevation at all. This is because canyons and valleys do not impact the perception of flatness until you’re standing near the edge; anyone who’s been a mile away from the South Rim of the Grand Canyon can confirm that you don’t know its there.
Graphic displays the angular measure criteria (0.32 degree) used to make the binary flat/not flat classification.
The data processing for this project was massive, requiring downloading all the individual tiles of the SRTM for the Lower 48 (55 tiles, over 4GB in total size), importing (r.in.gdal), mosaicing (r.patch), setting regions (g.region), then ultimately subsetting into four sections because of a bug in r.horizon (r.mapcalc conditional statements), running r.horizon 16 times on every raster cell in the Lower 48 (1,164,081,047 cells), running the cut point reclassification (r.recode), then compiling the final index score (r.mapcalc). Each segment of the DEM took about 36 hours to process in r.horizon, meaning the entire Lower 48 took about 6 days total.
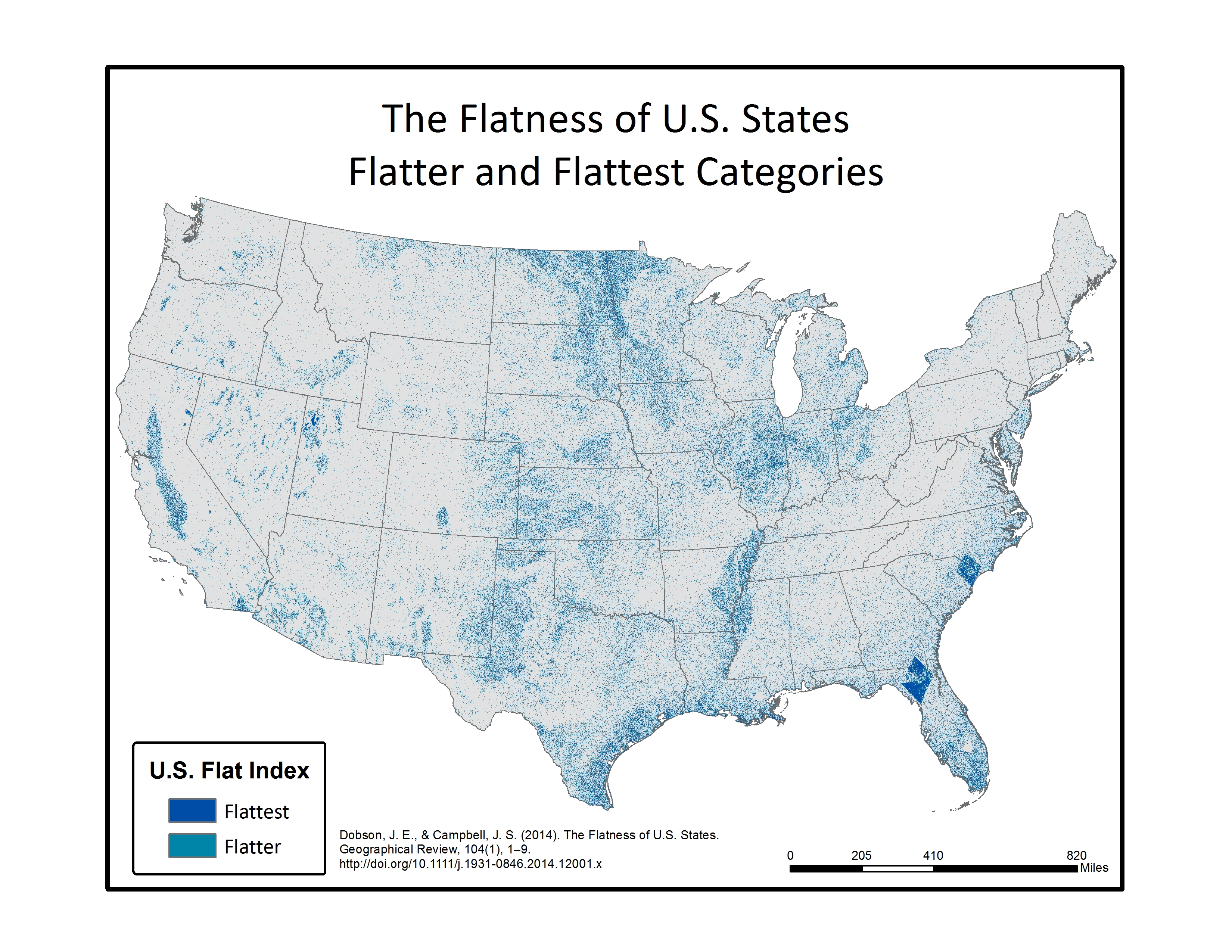
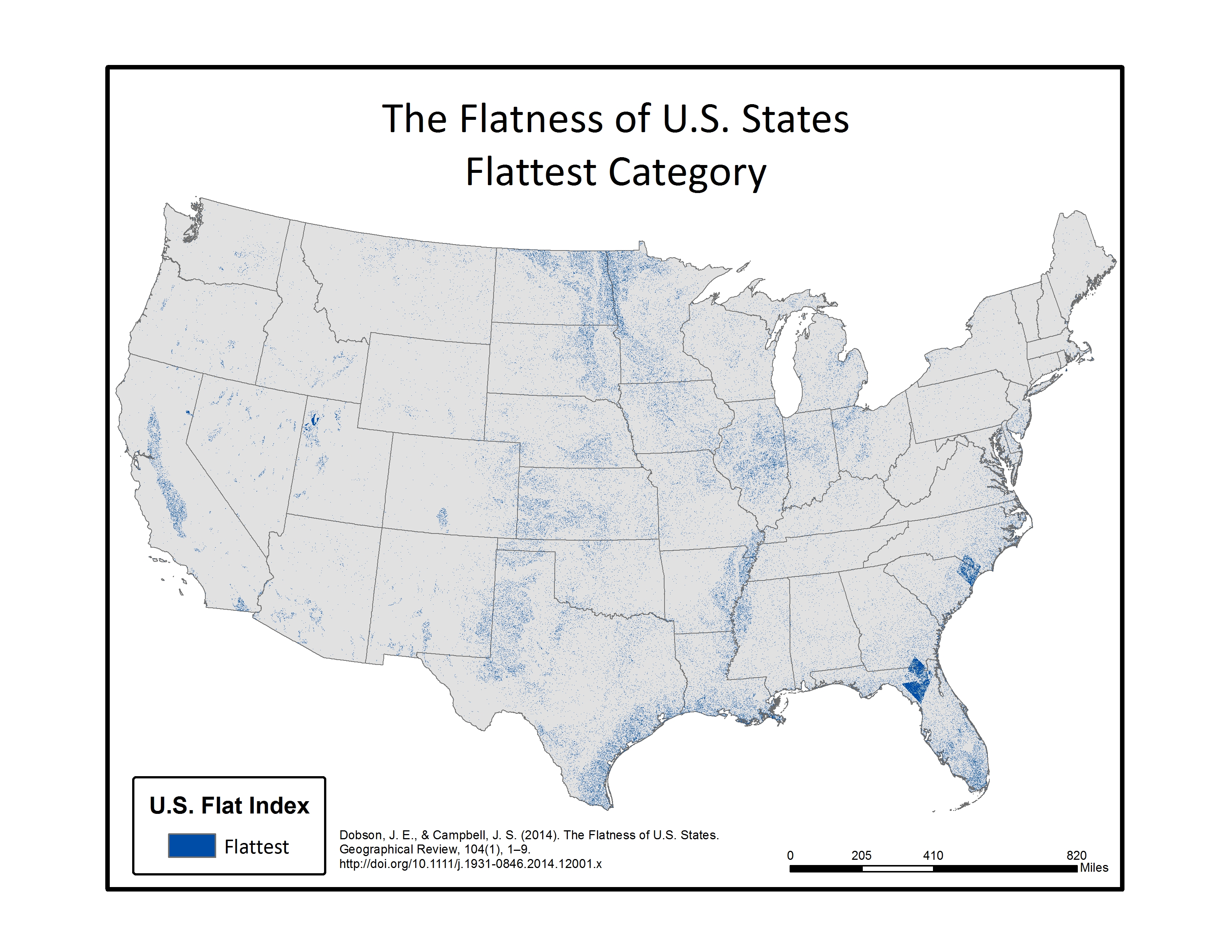
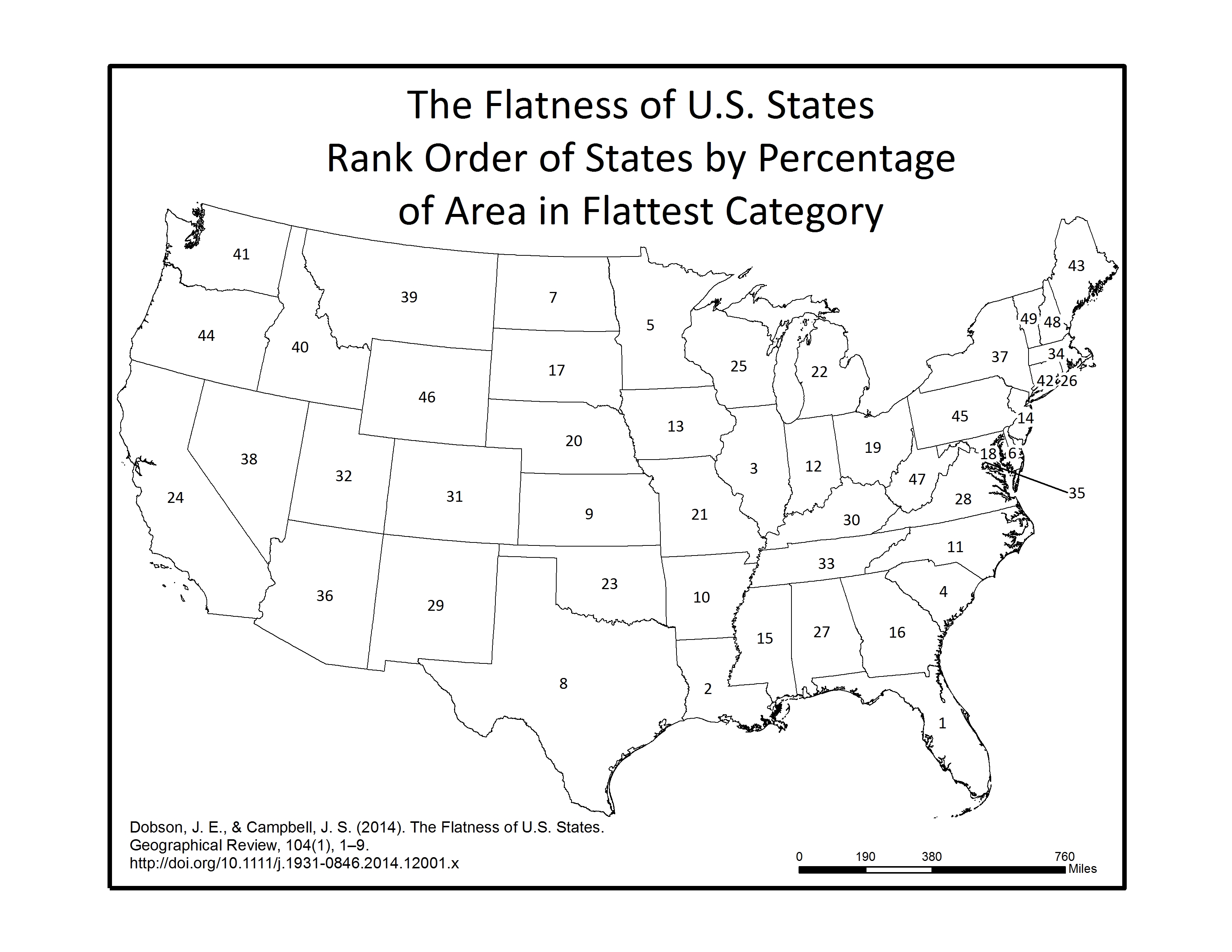
In the final step, each of the 16 individual azimuth scores were added together (r.mapcalc) to create a single index score ranging from 0-16 (0 being non-flat in all directions, 16 being flat in all directions). This index score was divided into four groupings, with Not Flat (0-4), Flat (5-8), Flatter (9-12), Flattest (13-16) categories. Zonal statistics (r.statistics) for each state were extracted from the final flat index, also known as the “Flat Map”, to calculate the rankings for flattest state. A water bodies data layer was used as a mask in the zonal statistics (r.mask) so as to eliminate the impact of flat surface water elevations (reservoirs and lakes) from the final calculation. A second mask was also used to eliminate the influence of two areas of bad data located in the southeastern U.S., mainly in Florida and South Carolina. Both total number of flat pixels and percent area flat pixels were calculated and ranked for the flat, flatter, and flattest categories. See the article below for a table of results.
Results
Below are a series of maps that display the final Flat Index. The spatial distribution of flat areas is intriguing, with some confirmations and surprises to our initial hypotheses. Interesting areas include the Piedmont and coastal plains of the eastern coastal states, Florida and the coastal areas of the Gulf States, the Red River Valley in Minnesota and North Dakota, the glacial outwash in Illinois and Indiana, the Lower Mississippi River valley, the High Plains region of the Great Plains, the Basin and Range country of the Intermontain West, and the Central Valley of California. A complete table of the state rankings is available in the article, and there are several more zoomed in maps available below. Each image is clickable and will open a much larger version.
Map shows the Flat Index, a.k.a the “Flat Map”, for the Lower 48 of the United States.Map displays the Flatter and Flattest Categories of the Flat Index. Useful for visualizing the patterns of flat lands within the continental United States.Map displays the Flattest Category of the Flat Index. These are the areas that can be called “flat as a pancake.”Rank order of States by the percentage of their area in the Flattest class. As initially thought, Kansas isn’t even close to the flattest.
Media
The media response to what Jerry Dobson, my coauthor and PhD advisor, and I refer to as the “Flat Map” took me by surprise. Jerry was always confident it would be well received, but the range of international, national, and regional coverage it received was beyond anything I imagined…and it keeps going.
As an added bonus, in the spring of 2017 renowned science blogger Vsauce featured the Flat Map in the a video about “How Much of the Earth Can You See at Once” (see video below). With over 4.5M views so far, this has to be most coverage the Flat Map has received. I recommend the entire video, and the Flat Map section begins around the 10:30 mark.
And this little gem from the 2015 Kansas Official Travel Guide…that’s right, the Flat Map made the Tourism Guide. In the very chippy AIR response to the Flat Map, the AIR editors indicate they got a call from the Kansas Director of Tourism. I’ll take this.
Does the perception of flatness impact tourism? Seems the State of Kansas is interested in projecting that the Kansas landscape has hills.
More Maps
Map shows the Flat Index for the Lower 48 of the United States overlaid with the boundaries of the USGS Physiographic regions. Interesting correlation between flat areas and physiographic boundaries.Map displays the Flat Index over Florida, note large areas of flat land in southern half of the state and along the panhandle coast.Map shows the Flat Index over Louisiana and the Lower Mississippi Valley. Large areas of flat lands occur within the river valley and along the coastal areas.Map shows the Flat Index over Illinois and Indiana. Note the huge area of Illinois within the Flattest class, the result of glacial outwash geomorphic processes.Map shows the Flat Index over northern Texas and Oklahoma. Note large tracts of flat land in the western High Plains region.Map shows the Flat Index over Kansas. Note large areas of flat land in the western High Plains region and in the central area of the state corresponding to the Arkansas River valley and McPherson-Wellington Lowlands physiographic province.
Thanks
I would like to thank Dr. Jerry Dobson for his efforts on this paper. We worked together conceptualizing “flat” and how to build a novel, terrain-based, and repeatable method for measuring it. It was a long road to get the Flat Map out to the world, and Jerry was a constant source of inspiration and determination to get it published. When I was swamped with work at the State Department, Jerry pushed forward on the write up and talking with the media.
Future
In terms of the future, there is much more that can be done here. New distributed raster processing tools (Mr. Geo and GeoTrellis) could rapidly increase processing speeds, and provide an opportunity for using a more refined, multi-scalar approach to flatness. New global elevation datasets are also becoming available, and could potentially reduce the error of the analysis through lower margins of error in forested areas. If I was to do it again, the USGS National Elevation Datasets, particularly at the 30 meter and even 10 meter resolution, would be a great option for the United States. On the perception front, the terrain analysis results could be compared with landcover data to determine how landcover affects perception. Social media polling could also gather a huge amount of place-based data on “Is your location flat?” and “Is your location boring?”. I would also like to get the data hosted on web mapping server somewhere, so people could interact with it directly. A tiled map service and the new Cesium viewer would be a great tool for exploring the data. If anyone is interested in working together, let me know.
Article
Below is a pre-publication version of the article submitted to Geographical Review. Please cite the published version for any academic works.
While most advanced linux users will find this post elementary, as a ‘know enough to be dangerous’ linux user I often struggle with the simple tasks. With that in mind, this is a brief summary of the steps required to install QGIS and GRASS on Ubuntu 10.04.
The instructions provided by both the QGIS and GRASS websites are actually quite good, but there are a couple steps that intro users might miss. In terms of the workflow, the process is as such:
1. Add a new software repository
2. Reload the repository (note: this is what they don’t tell you)
3. Install software
Step 1: Add a new software repository
It appears there are a couple ways to do this: GUI, modify the /etc/apt/sources.list file, and through terminal. Since the directions on the QGIS and GRASS websites use the terminal approach, I did as well and then checked the results through the GUI.
In my case, running these commands in sequence resulted in a error: “Package qgis is not available…” So to check what is happening I looked at the Software Sources (System–>Administration–>Software Sources) and specifically the second tab “Other Software”. If the second line of the code above executed, you will have a reference to “http://ppa.launchpad.net/ubuntugis/ubuntugis-unstable/ubuntu”. This is the correct URL that Ubuntu should look at to find the required binaries, but something is off.
The problem is that Ubuntu does not automatically check the repository for the software contained within it. To force an update, you have two choices. First is to use the GUI: Select the ppa.launchpad.net reference, then select ‘Edit’, don’t change anything, then select ‘Close’. The GUI will prompt that it needs to refresh, select yes. The second option would be to run: sudo apt-get update (I think). Either way, once the update completes, you can run the ‘sudo apt-get install qgis’ and it will install correctly. To install GRASS, run the command ‘sudo apt-get install grass’
I am working on the final stages of the long-delayed ‘Flat Map’ and needed to get the latest versions of the open-source GIS stack up and running. Processing for the continental U.S. is complete, the remaining steps include the creation of the index and the zonal statistics by state. Hope to have it completed by the end of October.
GIS Day 2009 at the University of Kansas was an unquestionable success. Now in its 8th year the GIS Day Symposium continued its trend of bringing a quality mix of speakers to the university and attracting a diverse crowd from academia, government, and business. The speaker selection was balanced and had elements of GIS data structures for moving objects, open source software, biological conservation, transportation infrastructure modeling, and flood inundation modeling. The information fair (which started three years ago) had the largest vendor participation yet and the modified location in the Kansas Union, to the main lobby on the fourth floor for the information fair and Alderson Auditorium for the talks was a nice pairing. I am continually impressed with the quality of work presented in the student competition (full disclosure: I participated this year as well, more on this below).
This was the first year in the last six that I didn’t have a significant hand in the planning of GIS Day. While initially I wondered what would happen to the day, I can safely say this year was one of the best. Eric Weber (a MA student in Geography) stepped up to continue the tradition of Geography graduate student leadership, and Xan Wedel (KU Institute for Policy and Social Research), Rhonda Houser (KU Libraries), Joel Plummer (KU PhD Candidate in Geography), and Xingong Li (KU Professor in Geography) continued with their longstanding efforts as members of the Planning Committee. I can assure you that it is not easy to plan and execute a GIS Day and these folks (along with the other KU geography graduate students who helped out) deserve a lot of thanks for putting in the effort.
Personally, it was extremely gratifying that all of our hard work in previous years carried through in this the first year that didn’t involve either myself or Matt Dunbar (who was integral to GIS Day for the first five years). As a tongue-in-cheek joke, but I hope also sincere gesture, the long-term members of the planning committee listed above surprised me with a ‘Lifetime Achievement Award’ for significant contributions to the Geography and GIS communities at KU. While I recognize the intended humor in this, I really do appreciate my colleagues recognition of the many years of effort I put into GIS Day. If this year is any measure, we’ve created a framework for success and built something that can last into the future.
The presentation and videos for the day will be available on the GIS Day website in the coming weeks. My presentation is available at this link. The final report of the project and data files will be posted later.